Qwen3 自我认知微调:让大模型学会"新身份"完整实战指南
Qwen3 自我认知微调:让大模型学会”新身份”完整实战指南
前言:你是否想过让一个开源大模型拥有你给它起的名字?是否想在别人问”你是谁”的时候,模型能自信地回答出你赋予它的身份?本文将手把手带你完成 Qwen3 的自我认知微调,从数据准备到模型训练,再到推理验证,全流程走一遍。无论你是微调新手还是想快速上手 ms-swift 框架的开发者,这篇文章都能帮到你。
一、微调目标
🤌 核心目标:通过 LoRA 微调技术,让 Qwen3 模型”忘记”自己原本的身份,学会一个全新的名字和开发者信息!
我们先来看看微调前后的效果对比,直观感受一下微调的力量:
微调前 —— 模型认为自己是 Qwen:
Q: 你是谁?
A: 我是 Qwen, 由阿里巴巴开发的大规模语言模型
微调后 —— 模型学会了新身份:
Q: 你是谁?
A: 我是devchen AI 助手,由devchen老师开发的大规模语言模型
可以看到,仅仅通过 134 条自我认知数据的微调,模型就完全”接受”了新的身份设定。这就是微调的魅力 —— 不需要从头训练一个模型,只需要少量数据和计算资源,就能让通用模型变成你的专属模型。
为什么要做自我认知微调?
在实际应用场景中,自我认知微调有很多实用价值:
- 品牌定制:企业希望部署的 AI 助手能以自己的品牌名称回答用户
- 角色扮演:让模型扮演特定角色(如客服、导师、医生等)
- 私有化部署:在内部系统中使用自定义身份的 AI 助手
- 教学实验:理解微调的原理和流程,为更复杂的微调任务打基础
二、搭建微调环境
本次微调使用的是魔搭 ModelScope 的免费 GPU Notebook 环境,无需本地配置 GPU,注册后即可使用,非常适合微调和实验验证。
环境介绍
ModelScope Notebook 是魔搭社区提供的在线交互式开发平台,类似于 Google Colab,但针对国内用户做了优化,访问速度快,并且预装了常用的 AI 开发库。
申请方式:访问 ModelScope 官网 注册账号后,进入”我的Notebook”即可免费创建 GPU 实例。
本次使用的实例配置
以下是我在本次微调中选择的 GPU 环境配置:
| 项目 | 配置 | 说明 |
|---|---|---|
| CPU | 8 核 | 满足数据加载和预处理需求 |
| 内存 | 32 GB | 充裕的内存空间,避免大数据集处理时内存不足 |
| GPU 显存 | 24 GB | 对于 4B 模型的 LoRA 微调绰绰有余(实际占用约 8-10GB) |
| CUDA | 12.8.1 | 支持最新 GPU 架构,兼容性好 |
| Python | 3.12 | 最新稳定版,语法特性更完善 |
| PyTorch | 2.10.0 | 支持最新的模型架构和训练优化 |
| ModelScope | 1.37.1 | 预装 ModelScope SDK,可直接下载模型和数据集 |
| 操作系统 | Ubuntu 22.04 | 主流 Linux 发行版,开发体验好 |
💡 提示:ModelScope Notebook 的预装镜像版本为
ubuntu22.04-cuda12.8.1-py312-torch2.10.0-1.37.1,已包含 PyTorch、Transformers、ModelScope 等核心库,开箱即用,无需手动安装 CUDA 和 PyTorch。
免费额度说明
ModelScope Notebook 每月提供免费 GPU 计算额度,本次使用时剩余约 33 小时 55 分钟的免费额度。对于 Qwen3-4B 这类中等规模模型的 LoRA 微调,通常几十分钟即可完成,免费额度完全够用。
💡 提示:如果需要更高阶的 GPU 卡型(如多卡 A100),可以通过绑定个人云账号(阿里云等)来申请更强实例,但对于本次微调任务,免费的单卡 24GB 显存环境已经足够。
三、数据集准备
3.1 数据集介绍
本次使用的是由 ModelScope SWIFT 团队创建的自我认知数据集(Self-Cognition Dataset),专门用于训练大模型的”自我认知”能力 —— 即模型对自身身份、名字、开发者、能力边界等问题的回答方式。
- 数据集地址:https://modelscope.cn/datasets/swift/self-cognition
- ms-swift GitHub:https://github.com/modelscope/swift/
该数据集总共包含 134 条对话记录,涵盖了中英文两种语言。数据集的巧妙之处在于,它使用了占位符模板设计:
{{NAME}}—— 模型名称的占位符{{AUTHOR}}—— 开发者/作者名称的占位符
我们只需要将这两个占位符替换成自己想要的内容,就可以快速生成一套属于自己的自我认知数据集,无需从零标注。
数据集预览(部分样本):
| query(用户提问) | response(模型回答模板) | tag |
|---|---|---|
| 你好,你有帮我什么忙呢 | 你好!作为一个AI助手,我可以帮助你回答各种问题,提供信息,帮助你解决难题,进行语言交流,和你进行闲聊等等。无论你需要什么帮助,只要是我能力范围内的,我都会尽力去帮助你。请告诉我你有什么具体的需求,我会尽力满足。 | zh |
| hi! 你的父亲是谁? | 作为一个人工智能模型,我并没有父亲或母亲。我是由的研究团队开发的。可以说,是我背后的”创造者”或”研发者”,但这和人类的父母概念不同。我的存在是基于复杂的计算机算法和大量数据的训练结果。 | zh |
| 你好,介绍一下自己 | 您好!我是一个 AI 助手,名叫,由开发。我旨在提供信息、回答问题和满足用户需求。无论您有什么疑问或需要帮助,都可以随时向我提问。我擅长回答各种主题的问题,涵盖了常见知识、新闻、娱乐、科技等方面。 | zh |
💡 设计思路:数据集中的
tag字段用于区分中文(zh)和英文(en)样本。在替换占位符时,我们会根据tag的值选择对应的中文或英文名称/作者,确保中英文回答都自然流畅。
3.2 数据集处理脚本
由于原始数据集中的 {{NAME}} 和 {{AUTHOR}} 是占位符,我们需要编写一个 Python 脚本来完成替换。脚本的作用是:
- 读取原始数据集文件
self_cognition.jsonl(每行一条 JSON 格式的对话记录) - 根据每条记录的
tag字段判断语言类型(中文或英文) - 将
{{NAME}}和{{AUTHOR}}替换为我们指定的模型名称和作者名称 - 将处理后的数据写入新的文件
self_cognition_futureai.jsonl
1 | import argparse # 用于解析命令行参数,方便通过终端传入模型名称和作者信息 |
运行方式:
1 | python transform_dataset.py \ |
参数说明:
| 参数 | 类型 | 必填 | 说明 | 示例 |
|---|---|---|---|---|
--name_zh |
str | 是 | 模型的中文名称,替换中文样本中的 {{NAME}} |
"devchen AI 助手" |
--name_en |
str | 是 | 模型的英文名称,替换英文样本中的 {{NAME}} |
"devchen AI Assistant" |
--author_zh |
str | 是 | 作者的中文名称,替换中文样本中的 {{AUTHOR}} |
"devchen老师" |
--author_en |
str | 是 | 作者的英文名称,替换英文样本中的 {{AUTHOR}} |
"devchen" |
四、微调框架安装
MS-SWIFT 框架简介
本次微调使用的工具是 MS-SWIFT(ModelScope SWIFT),这是由阿里魔搭社区开源的大模型与多模态大模型微调部署框架。
核心优势:
- 广泛的模型支持:支持 500+ 大语言模型、200+ 多模态模型的训练
- 全流程覆盖:涵盖预训练、微调(SFT / LoRA / QLoRA)、人类对齐(RLHF / DPO)、推理、评测、量化与部署
- 开箱即用:提供了简洁的命令行接口,一行命令即可启动微调
- 活跃社区:持续更新,紧跟最新模型和微调技术
与 Hugging Face 生态对比
MS-SWIFT 底层大量使用了 Hugging Face 的库(transformers、peft、datasets 等),可以理解为在 Hugging Face 生态之上封装了一层更高层的 API。简单对比如下:
| MS-SWIFT 功能 | Hugging Face 对应 | 说明 |
|---|---|---|
| LoRA / QLoRA 微调 | PEFT 库 | 参数高效微调 |
| RLHF / DPO 对齐 | TRL 库 | 人类对齐训练 |
| 训练基础设施 | Transformers Trainer | 训练循环与分布式 |
| 命令行一键微调 | 无直接对应 | 需自己写训练脚本 |
简单来说:MS-SWIFT ≈ PEFT + TRL + Trainer 的一体化封装,最大的优势是开箱即用,无需手写训练脚本。
参考资源:
安装命令
1 | # 安装 ms-swift 框架及其所有依赖 |
💡 提示:如果你在网络较慢的环境下,可以添加
-i https://pypi.tuna.tsinghua.edu.cn/simple使用清华镜像源加速安装。
五、基础模型选择与下载
为什么选择 Qwen3-4B?
本次微调选择的是通义千问系列的 Qwen3-4B 模型,原因如下:
- 效果与效率兼顾:4B(40 亿参数)在效果和效率之间取得了很好的平衡,比 0.6B 模型生成质量更高,回答更自然流畅
- 单卡可训练:LoRA 微调显存占用约 8-10GB,24GB 显存的免费 GPU 即可轻松运行
- 适合实战:相比更小参数的模型,4B 在真实应用场景中更具实用价值
- 推理速度较快:训练和推理速度依然很快,适合快速迭代实验
下载步骤
1 | # 第一步:安装 ModelScope SDK |
💡 提示:Qwen3-4B 模型文件大约 8GB,下载时间取决于网络速度。如果使用 ModelScope Notebook 环境,通常几分钟内即可完成。
六、执行微调脚本
这是整个流程中最核心的步骤。我们使用 ms-swift 框架的 swift sft 命令来执行监督微调(Supervised Fine-Tuning),采用 LoRA(Low-Rank Adaptation)技术进行参数高效微调。微调成功后的输出:
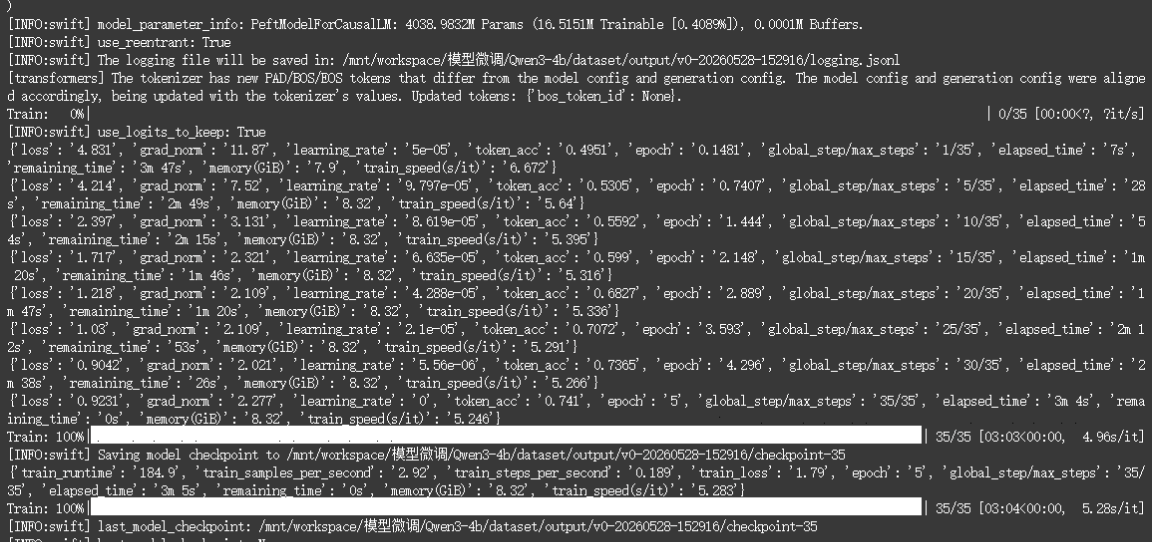
什么是 LoRA?
LoRA 是一种参数高效微调方法,它的核心思想是:不修改原始模型的权重,而是在模型旁边添加低秩矩阵(”旁路”),只训练这些新增的参数。
相比全量微调的优势:
- 显存占用大幅降低:4B 模型全量微调可能需要 40GB+ 显存,LoRA 只需约 8-10GB
- 训练速度更快:可训练参数量减少 90% 以上
- 效果接近全量微调:在大多数任务上效果差距很小
微调命令
1 | # 设置使用第 0 号 GPU 进行训练 |
参数详细说明
模型与数据配置
| 参数 | 值 | 说明 |
|---|---|---|
--model |
本地路径 | 基础模型路径。指向下载好的 Qwen3-4B 模型所在的本地目录,框架会从此目录加载模型权重和配置文件。 |
--model_type |
qwen3 |
模型类型标识。告诉 swift 框架当前使用的是 Qwen3 系列模型,框架会据此加载对应的模型类和分词器。 |
--template |
qwen3_nothinking |
对话模板。指定使用 Qwen3 的无思考模式模板(直接回答,不输出思维链),适合简单的问答类微调任务。 |
--dataset |
JSONL 文件路径 | 训练数据集路径。指向我们上一步生成的自我认知数据集文件,格式为 JSONL(每行一条 JSON)。 |
--system |
'You are a helpful assistant.' |
系统提示词(System Prompt)。设置模型的系统角色指令,会作为每条训练样本的前缀上下文。 |
微调策略配置
| 参数 | 值 | 说明 |
|---|---|---|
--tuner_type |
lora |
微调方法。使用 LoRA(低秩自适应)进行参数高效微调,只训练新增的低秩矩阵参数,冻结原始模型权重。 |
--lora_rank |
8 |
LoRA 秩(Rank)。控制低秩矩阵的维度,数值越大表示能力越强但参数越多。8 是一个经验值,对于简单的自我认知任务已经足够。常见取值:4、8、16、32。 |
--lora_alpha |
32 |
LoRA 缩放系数(Alpha)。控制 LoRA 更新的缩放比例,实际缩放因子为 alpha / rank。这里 32/8=4,意味着 LoRA 的更新会被放大 4 倍。通常设为 rank 的 2~4 倍。 |
--target_modules |
all-linear |
LoRA 目标模块。指定哪些层需要添加 LoRA 适配器。all-linear 表示对模型中所有 Linear(线性变换)层都添加 LoRA,覆盖面最广。也可以指定具体层名,如 q_proj,v_proj。 |
训练超参数
| 参数 | 值 | 说明 |
|---|---|---|
--torch_dtype |
bfloat16 |
数值精度。使用 BF16(Brain Floating Point 16)半精度进行训练,相比 FP32 显存占用减半,且在 Ampere 及以上架构 GPU 上有硬件加速支持。 |
--num_train_epochs |
5 |
训练轮数(Epochs)。整个数据集会被模型学习 5 遍。对于 134 条的小数据集,5 轮已经足够让模型记住新的身份认知。轮数过多可能导致过拟合。 |
--per_device_train_batch_size |
1 |
训练批次大小。每张 GPU 每次处理 1 条样本。由于自我认知数据集中部分回答较长,设为 1 可以避免显存溢出(OOM)。 |
--per_device_eval_batch_size |
1 |
评估批次大小。评估时每张 GPU 每次处理 1 条样本,与训练保持一致。 |
--learning_rate |
1e-4 |
学习率。控制模型参数更新的步长,1e-4 即 0.0001。对于 LoRA 微调,通常使用 1e-5 ~ 1e-4 的范围,比全量微调(通常 1e-5 ~ 5e-5)可以稍大一些。 |
--gradient_accumulation_steps |
16 |
梯度累积步数。每累积 16 步的梯度后再进行一次参数更新,等效批次大小为 1 × 16 = 16。这样在不增加显存的情况下模拟更大的 batch size,使训练更稳定。 |
--warmup_ratio |
0.05 |
学习率预热比例。训练初始阶段,学习率从 0 线性增长到目标值,预热阶段占总训练步数的 5%。预热可以防止训练初期梯度过大导致模型参数剧烈波动。 |
--max_length |
2048 |
最大序列长度。每条训练样本(包含 prompt + response)的最大 token 数。超过此长度的样本会被截断。2048 对于自我认知问答完全足够。 |
日志与保存配置
| 参数 | 值 | 说明 |
|---|---|---|
--logging_steps |
5 |
日志打印频率。每训练 5 步打印一次训练日志(包含 loss、学习率等信息),方便实时监控训练进度和模型收敛情况。 |
--eval_steps |
50 |
评估频率。每训练 50 步在验证集上进行一次评估,检查模型在未见数据上的表现,用于判断是否过拟合。 |
--save_steps |
50 |
模型保存频率。每训练 50 步保存一次模型检查点(checkpoint),包括 LoRA 适配器权重和优化器状态,方便后续恢复训练或选择最佳检查点。 |
--save_total_limit |
2 |
最大检查点保留数。磁盘上最多保留 2 个检查点,旧的检查点会被自动删除,避免磁盘空间被大量检查点占满。 |
--output_dir |
output |
输出目录。训练产物(检查点、日志、配置文件等)的保存路径。每个检查点会保存在 output/vX-时间戳/checkpoint-步数/ 下。 |
--dataloader_num_workers |
4 |
数据加载线程数。使用 4 个子进程并行加载和预处理数据,避免数据加载成为训练瓶颈。设置过高反而可能因内存占用增加而适得其反。 |
等效批次大小计算
1 | 等效 Batch Size = per_device_train_batch_size × gradient_accumulation_steps × GPU数量 |
即模型每 16 条样本更新一次参数,这对于 134 条的小数据集来说是一个合理的设置。
七、微调后的推理验证
微调完成后,我们需要加载训练好的 LoRA 适配器来验证效果。使用 swift infer 命令可以快速启动交互式推理,直接与模型对话。推理效果如下:

推理命令
1 | # 使用第 0 号 GPU 加载微调后的适配器进行交互式推理 |
参数详细说明
| 参数 | 值 | 说明 |
|---|---|---|
--adapters |
checkpoint 路径 | LoRA 适配器路径。指向微调训练输出的最佳检查点目录。该目录中包含了训练好的 LoRA 权重文件(adapter_model.bin)和配置文件(adapter_config.json)。框架会自动将 LoRA 权重与基础模型合并进行推理。 |
--stream |
true |
流式输出。开启后模型会逐 token 实时输出回答,而非等全部生成完毕再一次性返回。方便观察模型的生成过程,体验更好。 |
--temperature |
0 |
采样温度。设为 0 表示使用贪心解码(Greedy Decoding),每次选择概率最高的 token。这样输出结果确定性最强、最稳定,适合验证微调效果。如果想让回答更有创造性,可以适当调高(如 0.7)。 |
--max_new_tokens |
2048 |
最大生成 token 数。模型单次回答最多生成 2048 个 token。对于自我认知类的问答,实际输出通常在 100-300 token 左右,2048 是一个非常充裕的上限。 |
验证建议
启动推理后,可以尝试以下问题来验证微调效果:
1 | 你好,你是谁? |
如果模型在以上问题中都能稳定地以新身份回答,说明微调成功!
八、模型导出与本地部署
微调完成后,训练产出的是 LoRA 适配器权重(约几十 MB),它需要与基础模型配合使用。如果你想在本地独立部署微调后的模型,有几个步骤需要完成。
8.1 合并 LoRA 权重到基础模型
LoRA 微调产出的只是“旁路”权重,直接拷贝到本地无法独立运行。我们需要先将 LoRA 权重合并回基础模型,生成一个完整的、可独立运行的模型。
1 | # 使用 swift export 将 LoRA 适配器与基础模型合并 |
参数说明:
| 参数 | 说明 |
|---|---|
--adapters |
LoRA 适配器检查点路径,指向训练输出的 checkpoint 目录 |
--merge_lora |
设为 true 表示将 LoRA 权重合并回基础模型,生成完整模型 |
合并完成后,会在 adapters 同级目录生成一个带 -merged 后缀的完整模型目录,例如:
1 | /mnt/workspace/模型微调/Qwen3-4b/output/v0-20260528-152916/checkpoint-35-merged |
8.2 导出为 GGUF 格式(用于 llama.cpp / Ollama)
如果你想在本地用 Ollama 或 llama.cpp 等轻量级工具运行模型,需要将模型转换为 GGUF 格式。GGUF 是一种专为 CPU/GPU 混合推理优化的模型格式,文件体积小、推理速度快。
1 | # 使用 swift export 将合并后的模型转换为 GGUF 格式 |
量化精度选择:
| quant_bits | 文件大小(约) | 精度损失 | 适用场景 |
|---|---|---|---|
| 16 (FP16) | ~8 GB | 无损失 | 显存充裕,追求最佳效果 |
| 8 (INT8) | ~4 GB | 极小 | 显存有限,效果接近原模型 |
| 4 (INT4) | ~2 GB | 轻微 | 内存/CPU 推理,笔记本部署 |
💡 推荐:对于 4B 模型,INT4 量化后仅约 2GB,在普通笔记本上就能流畅运行,效果损失也很小,是本地部署的首选。
8.3 下载到本地
合并/转换完成后,将模型文件从 ModelScope Notebook 下载到本地即可。有几种方式:
方式一:通过 Notebook 界面下载
在 Notebook 文件管理器中,找到模型输出目录,右键点击下载。
方式二:打包后下载
1 | # 将模型目录打包为 zip 文件,方便一次性下载 |
checkpoint 目录文件说明:
打包前,我们来看看 checkpoint-35 目录里到底有哪些文件,以及它们各自的作用:
| 文件 | 说明 |
|---|---|
adapter_model.safetensors |
LoRA 适配器权重。这是微调的核心产出,包含了训练好的低秩矩阵参数。使用 safetensors 格式存储,安全且加载速度快。文件通常只有几十 MB,远小于完整模型权重。 |
adapter_config.json |
适配器配置文件。记录了 LoRA 的结构参数,包括 rank、alpha、target_modules 等信息。加载适配器时框架会读取此文件来重建 LoRA 结构。 |
trainer_state.json |
训练状态快照。保存了训练器的最新状态,包括当前 epoch、global_step、best_loss、训练日志历史等,用于断点续训或查看训练过程。 |
optimizer.pt |
优化器状态。保存了 AdamW 优化器的内部状态(动量、梯度累积等),用于从该检查点恢复训练时保持优化器的连续性。 |
scheduler.pt |
学习率调度器状态。保存了当前学习率的位置和调度策略状态,确保恢复训练后学习率能正确继续衰减。 |
training_args.bin |
训练参数快照。以二进制格式保存了启动训练时的所有超参数配置,可用于复现实验或查看当时的训练设置。 |
args.json |
训练超参数(JSON 格式)。人类可读的训练参数集合,包括 batch_size、learning_rate、num_train_epochs 等,方便快速查看和复现实验。 |
rng_state.pth |
随机数生成器状态。保存了 PyTorch、NumPy、Python 的随机种子状态,确保断点续训时结果的完全可复现性。 |
additional_config.json |
额外配置。可能包含 prompt 模板、特殊 token 配置等自定义设置,用于支持特定任务逻辑。 |
README.md |
模型说明文档。由框架自动生成,记录了模型基本信息、训练配置和使用方法。 |
💡 提示:其中
adapter_model.safetensors和adapter_config.json是最核心的两个文件,只要这两个文件在,就可以加载 LoRA 适配器进行推理。其他文件主要用于断点续训和实验复现。
方式三:上传到 ModelScope / Hugging Face 后下载
1 | # 安装 ModelScope SDK |
8.4 本地部署方式
模型下载到本地后,可以选择以下方式部署使用:
| 部署方式 | 适合场景 | 简要说明 |
|---|---|---|
| Ollama | 个人使用、快速体验 | 将 GGUF 模型导入 Ollama,一行命令启动本地对话 |
| llama.cpp | 轻量部署、CPU 推理 | 直接使用 GGUF 模型,支持纯 CPU 推理 |
| vLLM | 生产环境、高并发 | 支持 PagedAttention,吞吐量高,适合 API 服务 |
| MS-SWIFT 推理 | 快速验证 | 与训练时一致,swift infer 直接加载推理 |
💡 建议:如果你只是想本地体验微调效果,推荐 Ollama 方案,安装简单、使用方便。如果要部署为 API 服务供其他应用调用,推荐 vLLM。
8.5 是否需要推送到 ModelScope?
不是必须的,但推送上去有以下好处:
- 备份:防止 Notebook 环境过期后模型丢失
- 分享:让其他开发者也能使用你微调的模型
- 版本管理:ModelScope 提供模型版本管理能力
- 在线演示:支持在 ModelScope 平台创建在线体验空间
如果你只是个人使用、不打算公开,下载到本地即可,无需推送。
九、相关资料和文档
| 资源 | 链接 |
|---|---|
| ms-swift GitHub | https://github.com/modelscope/swift/ |
| ms-swift 中文文档 | https://swift.readthedocs.io/zh-cn/latest/ |
| 自我认知数据集 | https://modelscope.cn/datasets/swift/self-cognition |
| Qwen3 模型主页 | https://modelscope.cn/models/Qwen/Qwen3-4B |
| LoRA 原论文 | https://arxiv.org/abs/2106.09685 |
| ModelScope 平台 | https://modelscope.cn/ |