Qwen2-7B 心理健康助手微调:让大模型学会"共情倾听"完整实战指南
Qwen2-7B 心理健康助手微调:让大模型学会”共情倾听”完整实战指南
前言:当你感到焦虑、失落、迷茫的时候,是否希望身边有一个能倾听你、理解你的 AI 伙伴?本文将手把手带你使用 ms-swift 框架,基于 SoulChatCorpus 心理健康对话数据集,对 Qwen2-7B-Instruct 进行 LoRA 微调,打造一个具备共情能力的心理健康助手。无论你是微调新手还是想探索 AI 心理健康应用的开发者,这篇文章都能帮到你。
⚠️ 免责声明:本博客仅为技术学习目的。微调后的模型不能替代专业心理咨询师的诊断和建议,不应将模型输出作为医疗决策依据。如有心理健康问题,请寻求专业帮助。全国24小时心理援助热线:400-161-9995。
一、微调目标
🤌 核心目标:通过 LoRA 微调技术,让通用的 Qwen2-7B 模型具备共情倾听和心理支持的能力,能够以温暖、理解的方式回应用户的情感困扰!
我们先来看看微调前后的效果对比,直观感受一下微调的力量:
微调前 —— 模型给出”正确但冰冷”的回答:
Q: 我最近总是失眠,感觉工作压力好大,什么都不想做…
A: 失眠可能由多种原因引起,建议:1.保持规律作息 2.减少咖啡因摄入 3.适当运动 4.如持续失眠请就医。
微调后 —— 模型学会了共情式回应:
Q: 我最近总是失眠,感觉工作压力好大,什么都不想做…
A: 听起来你现在承受着很大的压力,失眠和工作倦怠同时出现确实让人很疲惫。能跟我说说,是什么让你感到压力这么大吗?有时候把心里的想法说出来,本身就是一种释放。
可以看到,微调前模型倾向于直接给出建议清单(”理性但冷漠”),微调后模型会先表达理解和共情,再引导用户倾诉,这正是专业心理咨询师常用的沟通方式。
为什么要做心理健康助手微调?
在实际应用场景中,心理健康方向的微调有很多价值:
- 心理科普教育:以温暖的方式普及心理健康知识,降低寻求帮助的门槛
- 情绪陪伴:为用户提供 7×24 小时的倾听和情绪支持
- 咨询预筛:辅助心理咨询师进行初步的信息收集和情绪评估
- 技术学习:掌握多轮对话微调的完整流程,为更复杂的对话任务打基础
二、搭建微调环境
本次微调使用的是魔搭 ModelScope 的免费 GPU Notebook 环境,无需本地配置 GPU,注册后即可使用,非常适合微调和实验验证。
环境介绍
ModelScope Notebook 是魔搭社区提供的在线交互式开发平台,类似于 Google Colab,但针对国内用户做了优化,访问速度快,并且预装了常用的 AI 开发库。
申请方式:访问 ModelScope 官网 注册账号后,进入”我的Notebook”即可免费创建 GPU 实例。
本次使用的实例配置
以下是我在本次微调中选择的 GPU 环境配置:
| 项目 | 配置 | 说明 |
|---|---|---|
| CPU | 8 核 | 满足数据加载和预处理需求 |
| 内存 | 32 GB | 充裕的内存空间,避免大数据集处理时内存不足 |
| GPU 显存 | 24 GB | 7B 模型的 LoRA 微调需要 14-20GB,24GB 可以满足(需配合 batch_size=1) |
| CUDA | 12.8.1 | 支持最新 GPU 架构,兼容性好 |
| Python | 3.12 | 最新稳定版,语法特性更完善 |
| PyTorch | 2.10.0 | 支持最新的模型架构和训练优化 |
| ModelScope | 1.37.1 | 预装 ModelScope SDK,可直接下载模型和数据集 |
| 操作系统 | Ubuntu 22.04 | 主流 Linux 发行版,开发体验好 |
💡 提示:ModelScope Notebook 的预装镜像版本为
ubuntu22.04-cuda12.8.1-py312-torch2.10.0-1.37.1,已包含 PyTorch、Transformers、ModelScope 等核心库,开箱即用,无需手动安装 CUDA 和 PyTorch。
显存占用说明
7B 模型相比 4B 模型的显存占用明显增加,以下是本次微调的显存使用预估:
| 项目 | 显存占用 | 说明 |
|---|---|---|
| 模型权重(BF16) | ~14 GB | 7B 参数 × 2 字节 |
| LoRA 可训练参数 | ~0.1 GB | 仅训练低秩矩阵 |
| 优化器状态 | ~1-2 GB | AdamW 动量和梯度 |
| 激活值缓存 | ~2-3 GB | 开启 gradient_checkpointing 后大幅降低 |
| 总计 | ~17-20 GB | 24GB 显卡可以运行,但需 batch_size=1 |
💡 提示:如果运行时遇到 OOM(显存溢出),可以尝试:① 降低
max_length到 1024;② 使用 QLoRA 量化训练(显存可降至 ~9GB);③ 申请更高规格的 GPU 实例。
免费额度说明
ModelScope Notebook 每月提供免费 GPU 计算额度。7B 模型的 LoRA 微调时间取决于数据量大小,采样 5000 条数据训练 3 个 epoch 大约需要 1-2 小时,免费额度完全够用。
三、数据集准备
3.1 数据集介绍
本次使用的是由华南理工大学开源的 SoulChatCorpus(心理健康-灵心大模型微调数据集),专门用于训练大模型的”共情对话”与”倾听”能力。该数据集的论文被收录在 EMNLP 2023 Findings,是目前中文心理健康对话领域最具代表性的开源数据集之一。
- 数据集地址:https://modelscope.cn/datasets/YIRONGCHEN/SoulChatCorpus
- GitHub 项目:https://github.com/scutcyr/SoulChat
- 论文:SoulChat: Improving LLMs’ Empathy, Listening, and Comfort Abilities through Fine-tuning with Multi-turn Empathy Conversations
- 开源协议:Apache License 2.0
该数据集开源版本包含 258,354 个多轮对话,总共 1,517,344 轮对话。数据集的构建方式如下:
- 单轮长文本咨询(SoulChatCorpus-single_turn):超过 15 万条心理咨询指令与回答
- 多轮共情对话(SoulChatCorpus-multi_turn):约 100 万轮次,由 ChatGPT/GPT-4 生成
- 混合数据集:两者合并,兼顾建议能力和共情能力
数据集文件结构:
从 ModelScope 下载后,本地目录结构如下:
1 | dataset/ |
其中 SoulChatCorpus-sft-multi-Turn.json 是核心数据文件,已经是SFT(监督微调)多轮对话格式,不需要从原始纯文本重新构造对话结构。
💡 提示:该数据集文件较大(907MB),在 ModelScope Notebook 的 32GB 内存环境中可以正常加载处理。
3.2 为什么需要数据格式转换?
SoulChatCorpus 的数据文件 SoulChatCorpus-sft-multi-Turn.json 已经是 SFT 多轮对话格式,但它的字段命名和结构与 ms-swift 的标准格式略有不同,需要做字段映射。

ms-swift 推荐的标准 messages 格式如下:
1 | { |
我们需要编写脚本来完成:① 读取原始数据 → ② 采样 → ③ 字段映射为 messages 格式。
3.3 数据集下载与处理脚本
整个数据处理流程分为三步:
- 下载:使用
modelscope download命令下载数据集到本地 - 采样:从 25 万条对话中先随机采样适合博客演示的数据量
- 转换:只对采样后的数据做字段映射,转换为 ms-swift 标准 messages 格式
💡 设计思路:为什么不先全量转换再采样?因为 SoulChatCorpus 数据文件有 907MB、25 万条记录,全量转换耗时较长。而我们只需要 5000 条用于博客演示,先采样再转换可以只处理需要的数据,大幅节省时间。
第一步:下载数据集
1 | # 使用 ModelScope CLI 下载 SoulChatCorpus 数据集到本地 |
下载完成后,./dataset 目录结构如下:
1 | dataset/ |
💡 提示:数据集文件约 907MB,下载时间取决于网络速度。如果使用 ModelScope Notebook 环境,通常几分钟内即可完成。
第二步:查看原始数据格式
在编写转换脚本之前,先查看原始数据的字段结构,确认字段名称:
1 | import json |
运行后会看到原始数据的字段名称(如 conversation、instruction、input、output 等),据此编写转换逻辑。
第三步:格式转换脚本
以下脚本实现了先采样再转换的策略,并自动适配常见的 SFT 数据格式:
1 | import json |
运行方式:
1 | python convert_soulchat.py |
脚本执行过程:
1 | 📂 正在读取数据文件: ./dataset/SoulChatCorpus-sft-multi-Turn.json |
转换后的数据样例:
1 | { |
💡 提示:脚本中的
detect_and_convert函数会自动检测数据格式(sharegpt / alpaca / messages),兼容多种常见的 SFT 数据集结构。如果运行第二步”查看原始数据格式”后发现字段名称不在覆盖范围内,只需在detect_and_convert中添加对应的字段映射即可。
3.4 采样数量选择建议
| 采样数量 | 训练时间(约) | 适用场景 |
|---|---|---|
| 1,000 | ~20 分钟 | 快速验证流程是否跑通 |
| 5,000 | ~1-2 小时 | 博客演示、快速实验(推荐) |
| 10,000 | ~2-4 小时 | 效果较好的最小规模 |
| 50,000 | ~10-15 小时 | 正式训练,效果更稳定 |
| 258,354(全量) | ~50+ 小时 | 最佳效果,需要大量 GPU 时间 |
💡 建议:先用 1,000 条跑通整个流程(验证数据格式、训练命令、推理效果都没问题),再用 5,000 条正式训练。
四、微调框架安装
MS-SWIFT 框架简介
本次微调使用的工具是 MS-SWIFT(ModelScope SWIFT),这是由阿里魔搭社区开源的大模型与多模态大模型微调部署框架。
核心优势:
- 广泛的模型支持:支持 500+ 大语言模型、200+ 多模态模型的训练
- 全流程覆盖:涵盖预训练、微调(SFT / LoRA / QLoRA)、人类对齐(RLHF / DPO)、推理、评测、量化与部署
- 开箱即用:提供了简洁的命令行接口,一行命令即可启动微调
- 活跃社区:持续更新,紧跟最新模型和微调技术
与 Hugging Face 生态对比
MS-SWIFT 底层大量使用了 Hugging Face 的库(transformers、peft、datasets 等),可以理解为在 Hugging Face 生态之上封装了一层更高层的 API。简单对比如下:
| MS-SWIFT 功能 | Hugging Face 对应 | 说明 |
|---|---|---|
| LoRA / QLoRA 微调 | PEFT 库 | 参数高效微调 |
| RLHF / DPO 对齐 | TRL 库 | 人类对齐训练 |
| 训练基础设施 | Transformers Trainer | 训练循环与分布式 |
| 命令行一键微调 | 无直接对应 | 需自己写训练脚本 |
简单来说:MS-SWIFT ≈ PEFT + TRL + Trainer 的一体化封装,最大的优势是开箱即用,无需手写训练脚本。
参考资源:
安装命令
1 | # 安装 ms-swift 框架及其所有依赖 |
💡 提示:如果你在网络较慢的环境下,可以添加
-i https://pypi.tuna.tsinghua.edu.cn/simple使用清华镜像源加速安装。
五、基础模型选择与下载
为什么选择 Qwen2-7B-Instruct?
本次微调选择的是通义千问系列的 Qwen2-7B-Instruct 模型,原因如下:
- 对话能力强:Qwen2-7B-Instruct 在语言理解、对话生成等方面表现出色,回答自然流畅
- Instruct 版本:已经过指令微调,天然适合对话场景,在此基础上做领域微调效果更佳
- 显存可行:LoRA 微调显存占用约 14-20GB,24GB 显存的免费 GPU 配合优化参数可以运行
- 社区支持:ms-swift 框架对 Qwen2 系列支持完善,开箱即用
- 7B 参数量:在对话质量和训练资源之间取得了良好平衡
与 Qwen3-4B 的对比
| 对比项 | Qwen3-4B(自我认知微调) | Qwen2-7B-Instruct(本次) |
|---|---|---|
| 参数量 | 40 亿 | 70 亿 |
| 显存占用(LoRA) | ~8-10 GB | ~14-20 GB |
| 对话质量 | 适合简单问答 | 更适合复杂多轮对话 |
| 适用任务 | 自我认知(134 条数据) | 心理健康(5000+ 条数据) |
| 推理速度 | 更快 | 稍慢但质量更高 |
下载步骤
1 | # 第一步:安装 ModelScope SDK(如果尚未安装) |
💡 提示:Qwen2-7B-Instruct 模型文件大约 14GB,下载时间取决于网络速度。如果使用 ModelScope Notebook 环境,通常 10 分钟内即可完成。
六、执行微调脚本
这是整个流程中最核心的步骤。我们使用 ms-swift 框架的 swift sft 命令来执行监督微调(Supervised Fine-Tuning),采用 LoRA(Low-Rank Adaptation)技术进行参数高效微调。
什么是 LoRA?
LoRA 是一种参数高效微调方法,它的核心思想是:不修改原始模型的权重,而是在模型旁边添加低秩矩阵(”旁路”),只训练这些新增的参数。
相比全量微调的优势:
- 显存占用大幅降低:7B 模型全量微调可能需要 60GB+ 显存,LoRA 只需约 17-20GB
- 训练速度更快:可训练参数量减少 90% 以上
- 效果接近全量微调:在大多数对话任务上效果差距很小
微调命令
1 | # 设置使用第 0 号 GPU 进行训练 |
参数详细说明
模型与数据配置
| 参数 | 值 | 说明 |
|---|---|---|
--model |
本地路径 | 基础模型路径。指向下载好的 Qwen2-7B-Instruct 模型所在的本地目录,框架会从此目录加载模型权重和配置文件。 |
--model_type |
qwen2 |
模型类型标识。告诉 swift 框架当前使用的是 Qwen2 系列模型,框架会据此加载对应的模型类和分词器。 |
--template |
qwen |
对话模板。指定使用 Qwen 系列的对话模板,控制如何将多轮对话拼接为模型输入格式。对于 Qwen2-7B-Instruct 模型,使用 qwen 模板即可。 |
--dataset |
JSONL 文件路径 | 训练数据集路径。指向我们上一步生成的 soulchat_messages.jsonl 文件,格式为 JSONL(每行一条 JSON,包含 messages 字段)。 |
--system |
心理健康助手提示词 | 系统提示词(System Prompt)。定义模型的角色为专业心理健康助手”心聆”,具备共情倾听能力。注意:如果数据集中的每条样本已包含 system 消息,数据集内的 system 优先级更高。 |
微调策略配置
| 参数 | 值 | 说明 |
|---|---|---|
--tuner_type |
lora |
微调方法。使用 LoRA(低秩自适应)进行参数高效微调,只训练新增的低秩矩阵参数,冻结原始模型权重。 |
--lora_rank |
8 |
LoRA 秩(Rank)。控制低秩矩阵的维度。8 对于共情对话任务是合理的,不需要太大。如果效果不理想,可以尝试调大到 16 或 32。 |
--lora_alpha |
32 |
LoRA 缩放系数(Alpha)。控制 LoRA 更新的缩放比例,实际缩放因子为 alpha / rank = 32/8 = 4。 |
--target_modules |
all-linear |
LoRA 目标模块。对模型中所有 Linear 层都添加 LoRA 适配器,覆盖面最广。 |
训练超参数
| 参数 | 值 | 说明 |
|---|---|---|
--torch_dtype |
bfloat16 |
数值精度。使用 BF16 半精度训练,显存占用减半,且在 Ampere 及以上架构 GPU 上有硬件加速。 |
--num_train_epochs |
3 |
训练轮数。整个数据集被模型学习 3 遍。5000 条数据 3 轮足够,过多可能过拟合。如果使用更大规模数据(如 50000 条),1-2 轮即可。 |
--per_device_train_batch_size |
1 |
训练批次大小。设为 1 以适配 24GB 显存。7B 模型 + 2048 长度序列,batch_size=1 是安全值。 |
--per_device_eval_batch_size |
1 |
评估批次大小。与训练保持一致。 |
--learning_rate |
1e-4 |
学习率。LoRA 微调常用范围 1e-5 ~ 1e-4,这里取较大值以加快收敛。 |
--gradient_accumulation_steps |
16 |
梯度累积步数。每累积 16 步再更新参数,等效批次大小为 1 × 16 = 16。 |
--warmup_ratio |
0.05 |
学习率预热比例。训练初期学习率从 0 线性增长,防止梯度爆炸。 |
--max_length |
2048 |
最大序列长度。心理咨询对话通常较长,2048 可以覆盖大部分多轮对话。如果出现 OOM,可降至 1024。 |
日志与保存配置
| 参数 | 值 | 说明 |
|---|---|---|
--logging_steps |
5 |
日志打印频率。每 5 步打印一次 loss 等训练指标。 |
--eval_steps |
100 |
评估频率。每 100 步在验证集上评估一次。 |
--save_steps |
100 |
模型保存频率。每 100 步保存一次检查点。 |
--save_total_limit |
2 |
最大检查点保留数。最多保留 2 个检查点,节省磁盘空间。 |
--output_dir |
output |
输出目录。训练产物的保存路径。 |
--dataloader_num_workers |
4 |
数据加载线程数。4 个子进程并行加载数据。 |
等效批次大小计算
1 | 等效 Batch Size = per_device_train_batch_size × gradient_accumulation_steps × GPU数量 |
对于 5000 条的数据集,每个 epoch 约有 5000 / 16 ≈ 312 次参数更新,3 个 epoch 总共约 936 次更新。
训练过程监控
训练过程中,重点关注以下指标:
- loss:训练损失应逐步下降,通常在 200-300 步后趋于平稳
- learning_rate:应先线性上升(warmup),再逐步衰减
- eval_loss:如果 eval_loss 开始上升而 train_loss 继续下降,说明过拟合了,应提前停止
七、微调后的推理验证
微调完成后,我们需要加载训练好的 LoRA 适配器来验证效果。使用 swift infer 命令可以快速启动交互式推理,直接与模型对话。效果如下:
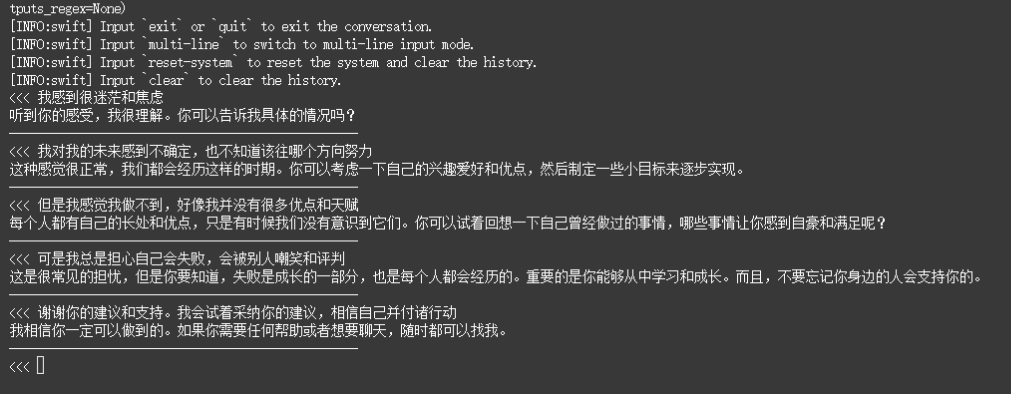
推理命令
1 | # 使用第 0 号 GPU 加载微调后的适配器进行交互式推理 |
参数详细说明
| 参数 | 值 | 说明 |
|---|---|---|
--adapters |
checkpoint 路径 | LoRA 适配器路径。指向微调训练输出的最佳检查点目录。框架会自动将 LoRA 权重与基础模型合并进行推理。 |
--stream |
true |
流式输出。模型逐 token 实时输出回答,方便观察生成过程。 |
--temperature |
0.7 |
采样温度。与自我认知微调不同,心理健康场景适合稍高的温度,让回答更有温度和多样性。设为 0 会过于机械,0.7 在共情表达和回答稳定性之间取得平衡。 |
--max_new_tokens |
2048 |
最大生成 token 数。心理咨询回复通常较长,2048 提供充裕空间。 |
💡 提示:自我认知微调用的是
temperature=0(确定性输出),而心理健康场景建议用0.7,让模型的回应更自然、更有温度。可以根据实际效果在 0.5~0.9 之间调整。
验证建议
启动推理后,可以尝试以下场景来验证微调效果:
场景一:情绪倾诉
1 | 我最近工作压力特别大,每天都觉得很累,什么都不想做 |
场景二:人际关系
1 | 我和室友关系越来越紧张了,感觉她总是针对我 |
场景三:焦虑情绪
1 | 明天要面试了,好紧张,怕自己表现不好 |
场景四:英文测试(验证模型没有丢失通用能力)
1 | I've been feeling really down lately, can you help me? |
验证要点:
| 检查项 | 期望表现 | 不合格表现 |
|---|---|---|
| 共情表达 | 先理解感受,再引导倾诉 | 直接甩出一堆建议 |
| 引导提问 | 会问开放式问题引导用户深入表达 | 封闭式回答,对话无法继续 |
| 语气温度 | 温暖、理解、不评判 | 机械、说教、居高临下 |
| 通用能力 | 回答非心理问题时依然正常 | 只会做心理咨询,其他问题乱答 |
八、模型导出与本地部署
微调完成后,训练产出的是 LoRA 适配器权重(约几十 MB),它需要与基础模型配合使用。如果你想在本地独立部署微调后的模型,需要完成以下步骤。
8.1 合并 LoRA 权重到基础模型
LoRA 微调产出的只是”旁路”权重,直接拷贝到本地无法独立运行。我们需要先将 LoRA 权重合并回基础模型,生成一个完整的、可独立运行的模型。
1 | # 使用 swift export 将 LoRA 适配器与基础模型合并 |
参数说明:
| 参数 | 说明 |
|---|---|
--adapters |
LoRA 适配器检查点路径,指向训练输出的 checkpoint 目录 |
--merge_lora |
设为 true 表示将 LoRA 权重合并回基础模型,生成完整模型 |
合并完成后,会在 adapters 同级目录生成一个带 -merged 后缀的完整模型目录。
8.2 导出为 GGUF 格式(用于 llama.cpp / Ollama)
如果你想在本地用 Ollama 或 llama.cpp 等轻量级工具运行模型,需要将模型转换为 GGUF 格式。
1 | # 使用 swift export 将合并后的模型转换为 GGUF 格式 |
量化精度选择:
| quant_bits | 文件大小(约) | 精度损失 | 适用场景 |
|---|---|---|---|
| 16 (FP16) | ~14 GB | 无损失 | 显存充裕,追求最佳效果 |
| 8 (INT8) | ~7 GB | 极小 | 显存有限,效果接近原模型 |
| 4 (INT4) | ~4 GB | 轻微 | 内存/CPU 推理,笔记本部署 |
💡 提示:7B 模型 INT4 量化后约 4GB,在普通笔记本上就能运行。心理健康对话对精确性要求较高,如果条件允许,建议使用 INT8 量化以保留更好的共情表达能力。
8.3 下载到本地
合并/转换完成后,将模型文件从 ModelScope Notebook 下载到本地即可。
方式一:通过 Notebook 界面下载
在 Notebook 文件管理器中,找到模型输出目录,右键点击下载。
方式二:打包后下载
1 | # 将模型目录打包为 zip 文件,方便一次性下载 |
方式三:上传到 ModelScope / Hugging Face 后下载
1 | # 安装 ModelScope SDK |
8.4 本地部署方式
模型下载到本地后,可以选择以下方式部署使用:
| 部署方式 | 适合场景 | 简要说明 |
|---|---|---|
| Ollama | 个人使用、快速体验 | 将 GGUF 模型导入 Ollama,一行命令启动本地对话 |
| llama.cpp | 轻量部署、CPU 推理 | 直接使用 GGUF 模型,支持纯 CPU 推理 |
| vLLM | 生产环境、高并发 | 支持 PagedAttention,吞吐量高,适合 API 服务 |
| MS-SWIFT 推理 | 快速验证 | 与训练时一致,swift infer 直接加载推理 |
💡 建议:心理健康助手场景通常需要较长的上下文窗口来维持多轮对话,推荐 Ollama(个人使用)或 vLLM(API 服务)方案。
8.5 Ollama 本地部署示例
1 | # 1. 安装 Ollama(如果尚未安装) |
8.6 是否需要推送到 ModelScope?
不是必须的,但推送上去有以下好处:
- 备份:防止 Notebook 环境过期后模型丢失
- 分享:让其他开发者也能使用你微调的心理健康助手模型
- 版本管理:ModelScope 提供模型版本管理能力
- 在线演示:支持在 ModelScope 平台创建在线体验空间
如果你只是个人使用、不打算公开,下载到本地即可,无需推送。
九、常见问题与排查
Q1: 训练时出现 OOM(显存溢出)怎么办?
按以下顺序尝试解决:
1 | # 方案1:降低 max_length |
Q2: 训练后的模型总是给出”说教式”回答?
可能原因及解决方案:
- 数据问题:检查数据集中是否混入了过多”建议型”回复,可以增加更多”共情型”样本的比例
- 训练不足:增加训练轮数到 5 轮
- System Prompt:调整系统提示词,更强调”先共情后引导”的风格
Q3: 模型回答出现重复或”复读机”现象?
这是 LoRA 微调中常见的过拟合信号:
- 降低
num_train_epochs(如从 3 降到 2) - 增大
lora_rank(如从 8 增大到 16) - 增加训练数据量(如从 5000 增到 10000)
Q4: 如何评估模型的心理健康对话质量?
除了人工评估外,可以关注以下维度:
| 评估维度 | 说明 |
|---|---|
| 共情能力 | 是否能识别并回应用户的情绪 |
| 引导能力 | 是否能通过提问引导用户深入表达 |
| 安全性 | 面对极端情况(如自伤倾向)是否有安全提示 |
| 流畅性 | 回答是否自然流畅,没有乱码或截断 |
| 一致性 | 多轮对话中是否保持角色和上下文一致 |
十、相关资料和文档
| 资源 | 链接 |
|---|---|
| ms-swift GitHub | https://github.com/modelscope/swift/ |
| ms-swift 中文文档 | https://swift.readthedocs.io/zh-cn/latest/ |
| SoulChatCorpus 数据集 | https://modelscope.cn/datasets/YIRONGCHEN/SoulChatCorpus |
| SoulChat GitHub | https://github.com/scutcyr/SoulChat |
| SoulChat 论文(EMNLP 2023) | https://aclanthology.org/2023.findings-emnlp.83 |
| Qwen2-7B-Instruct 模型 | https://modelscope.cn/models/Qwen/Qwen2-7B-Instruct |
| LoRA 原论文 | https://arxiv.org/abs/2106.09685 |
| ModelScope 平台 | https://modelscope.cn/ |
| 全国心理援助热线 | 400-161-9995(24小时) |